
v3 Code Review
We believe two things matter for great code review: catching bugs that would cause major harm if shipped to production, and not wasting developer time with incorrect comments, low-value suggestions, or noise.
Today we're releasing a new version of Macroscope Code Review (v3) that delivers a step-change improvement in both.
Summary
More Signal, Less Noise
Overall Precision
Dramatic improvement in precision, which means much fewer false positive comments
75%
98%
Signal to Noise
v3 leaves fewer comments overall whilst catching significantly more critical issues
22%
fewer comments
less noise
3.5x
more harmful bugs
detected in Typescript
What's New
Catching what matters
v3 detects up to 3.5x more bugs that would cause real production damage - guaranteed data loss, security breaches, crashes - the kind you'd block a PR over. These bugs are rare by nature; most PRs don't have them. But when they ship, they're potentially catastrophic. Across our benchmark, we catch 4 more of them for every 100 PRs reviewed than our previous version. That's 4 potential incidents that could have reached production.
Reducing Noise
Based on our benchmark, overall precision increased to 98% up from 75% (the percentage of review comments that were validated as correct), which translates to significantly fewer false positives. v3 also leaves 22% fewer comments overall, with 64% fewer nitpicks in Python and 80% fewer in TypeScript.
Benchmark Performance
Precision vs Recall
Curious how we achieved this? Read our technical deep dive. The short version: we combine an agentic approach with a system we call "auto-tune," which uses LLMs to automatically find the best-performing prompt, model, and language combination.
Universal file support
Previously, we only reviewed files in languages with native AST-parsing (~12 of the most popular). Now every file in your PR gets reviewed.
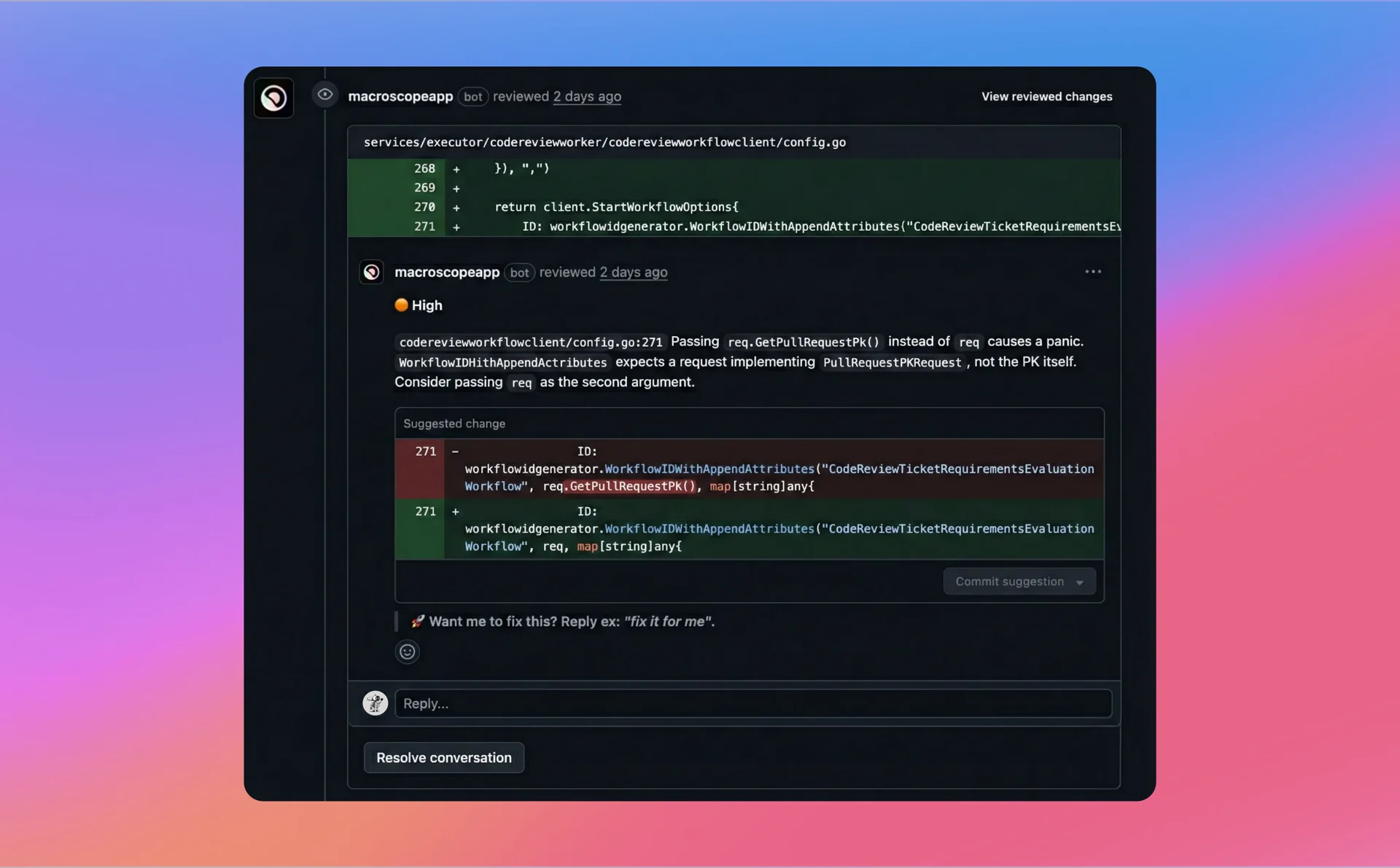
Severity levels
Macroscope now labels each review comment with a level of severity. Severity levels are labeled on every comment based on potential harm if shipped:
- 🔴 CRITICAL: Data lost or security breached if shipped—no recovery.
- 🟠 HIGH: Production crashes, hangs, or security degraded.
- 🟡 MEDIUM: Core functionality broken in production, but recoverable.
- 🟢 LOW: Cosmetic or edge-case issues users rarely notice.
Customer Impact
Benchmarks are one thing, real usage is another. Since launching this version, thumbs-up reactions increased 30% while comments per PR dropped 37%. Developers are also addressing 10% more of what we flag. Fewer comments, and better responses to the ones we leave. Better signal, less noise.
Customer Impact
Less is More
Thumbs Up Reactions
Devs 👍 more comments
+30%
Comments per PR
Devs see fewer overall comments
-37%
Addressed Rate
Devs resolve more comments
+10%
We're not done. You'll still see comments that miss the mark. Real-world codebases are messier and more varied than any test set. We're continuing to improve on both fronts: catching more of the bugs that matter, and reducing the comments that don't. If you encounter issues or have feedback, we want to hear it.
If you haven't tried Macroscope yet, we encourage you to sign up and get $100 in free usage. You're welcome to reach out on Slack, X, or email contact@macroscope.com with feedback — we'd love to hear from you.
